
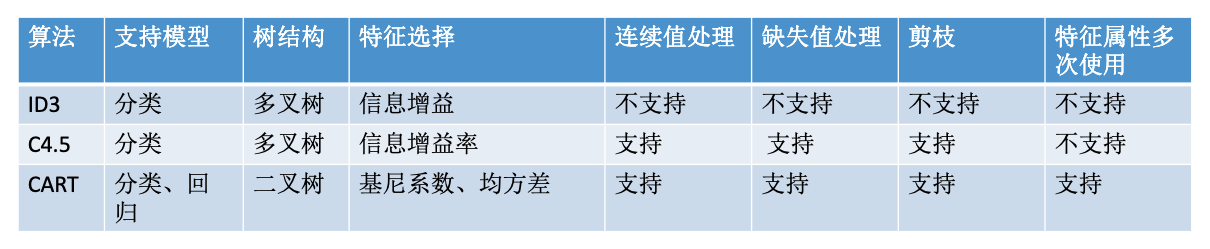
决策树基本定义
决策树是一种利用树形图进行决策的预测模型,表现出对象属性与对象值的一种映射关系,用于分类和回归任务。它是通过训练数据,采用自顶而下的贪婪算法选择最合适的属性作为节点生成的决策树。
属性选择标准
- 信息增益 (ID3算法)
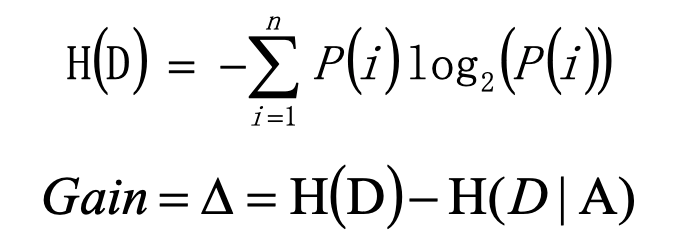
信息熵 H(D)用来描述系统信息量的不确定度,越混乱,信息熵越高。H(D|A)表示属性A的情况下的熵值。Gain值表示属性A对于系统统一性作出的贡献值,对比所有属性的Gain值,Gain值最高的属性适合做决策树的第一个节点。
条件熵:
eg. 风力weak的情况有8次,风力strong的情况6次。week情况下,8次中有6次出去玩,2次不出去玩。strong的情况下,6次中有3次出去玩,3次不出去玩。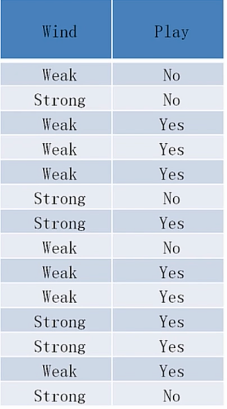
根据熵公式,
Entroy(weak) = -(0.25* $\log_2 0.25$) - (0.75* $\log_2 0.75$)= 0.8112781244591328
Entroy(strong) = -(0.5* $\log_2 0.5$) - (0.5* $\log_2 0.5$)= 1.0
1 | p玩=1/4 |
- 信息增益比率 (C4.5算法)
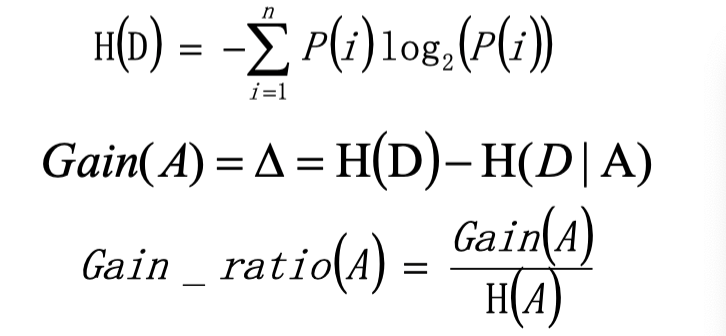
这种算法是ID3算法的进化,它排除了H(A)为0的情况,即如果有属性A发生的概率是1,就不使用这种属性作为决策树的节点。(如对象id这种属性,每一个值都是独特的,而它的对象映射的值也是确定的,因此概率是1。)
- 基尼系数/均方差 (CART算法 Classification and Regression Tree)
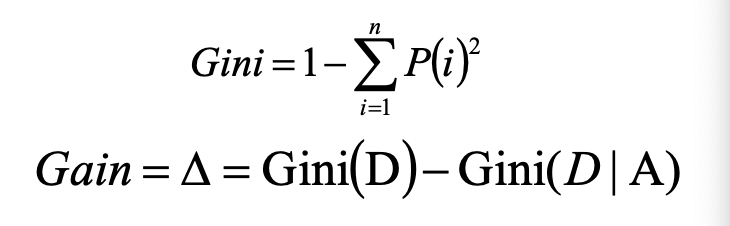
CART算法使用基尼系数(分类树)/均方差(回归树)作为属性节点的选择标准,选择GINI值最大的属性作为第一个节点,构建二叉树,越往下分,GINI值越小,代表分类效果越好。
分类树算法总结
分类树 vs 回归树
分类树采用信息增益、信息增益比率、基尼系数来评价树的效果,是基于概率值判断的。分类树节点的预测值取当前分类属性下sample数最多的那个类别。
回归树中,节点的预测值一般为节点属性中所有值的均值。一般采用MSE作为树的评价指标,即均方差。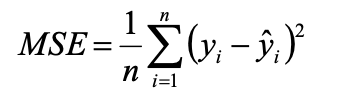
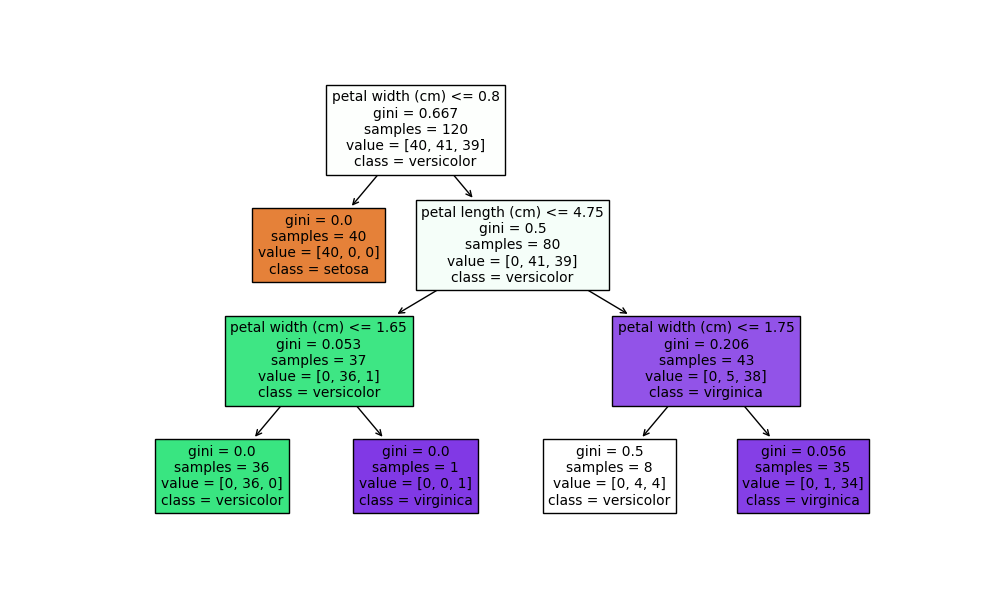
以sklearn中的iris数据集为训练集,使用决策树分类模型与回归模型,会直观得到以下:
决策树分类模型:
决策树回归模型:
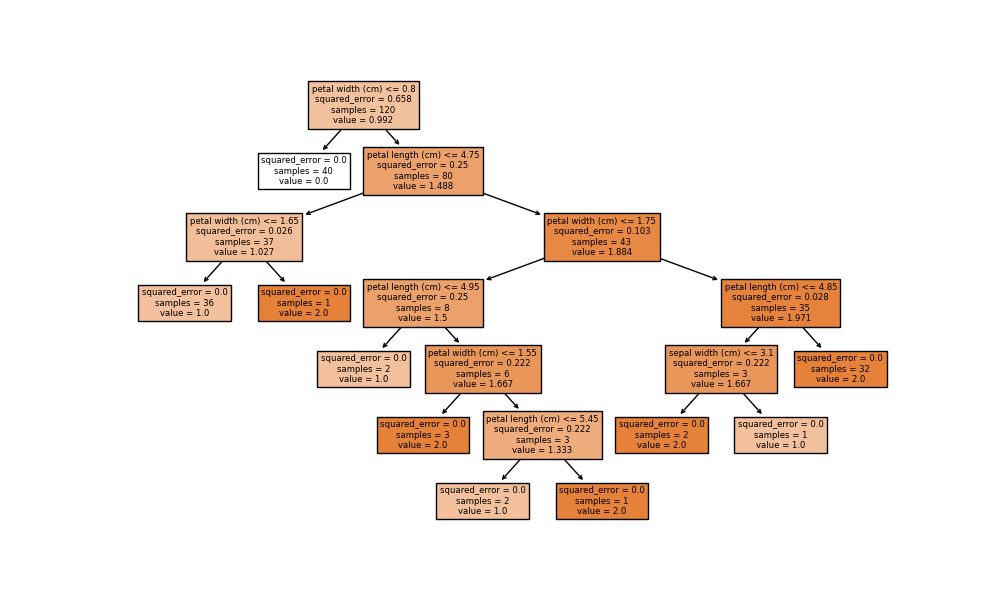
sklearn的iris数据集案例
共150组数据,其中120组为训练集,30组为测试集;每组数据有4个值,分别对应4个属性:sepal length,sepal width,petal length,petal width;3个类别:Setosa,Versicolour,Virginica。
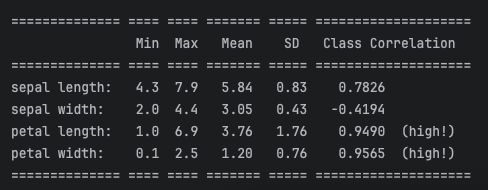
1 |
|